import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import causalpy as cp
print(f"CausalPy version: {cp.__version__}")
sns.set_style("whitegrid")
%config InlineBackend.figure_format = 'retina'Measure What Matters: Attribution vs Incrementality
Using CausalPy’s Interrupted Time Series to separate real performance changes from measurement updates
Imagine you’re running a subscription business. You rely on Meta Ads to drive sign-ups, and you monitor daily conversions closely. One morning, you open Ads Manager and see a sharp drop in reported conversions.
Panic sets in. Did something break? Did the algorithm shift? Should you cut spend?
Before you do anything, consider what actually changed.
On March 3, 2026, Meta announced a significant update to how it measures click-through attribution. In their post Simplifying Ad Measurement for a Social-First World, Meta explained that click-through attribution for website and in-store conversions will now exclusively include link clicks. Previously, Meta attributed conversions to all types of clicks: shares, saves, likes, and link clicks alike. That broader definition inflated click-through numbers relative to what third-party tools like Google Analytics would report.
Non-link-click actions (shares, saves, likes) are being moved to a newly renamed category: engage-through attribution (previously called engaged-view attribution).
Here is the critical part. In that same announcement, Meta themselves acknowledge that incrementality experiments are the real standard:
“Incrementality experiments, like Meta’s Conversion Lift, are the best way to address this question, and we believe that tests like these represent the gold standard in measurement.”
So the question is not whether Meta’s numbers dropped. The question is:
Did performance actually change, or did the measurement change?
The Problem with Platform Metrics
Platform-reported metrics are:
- Internally defined. The platform decides what counts as a conversion.
- Subject to change. As we just saw, definitions can shift overnight.
- Cookie-dependent. As privacy regulations tighten and browser restrictions increase, the signal that attribution relies on becomes less complete over time.
- Not equal to business outcomes. A reported conversion is not the same as a sign-up in your database.
This is not a Meta-specific problem. Every ad platform controls its own measurement definitions. Google, TikTok, LinkedIn. They all do it. The issue is treating these numbers as ground truth when they are, by design, approximations that the platform can redefine at any time.
If your measurement changes, your decisions will too, even if performance hasn’t.
That single sentence captures why platform attribution is a fragile foundation for decision-making.
What We Should Actually Measure
The ground truth for a subscription business is actual sign-ups: the events recorded in your own systems, independent of any ad platform’s reporting.
This distinction matters because attribution is not incrementality.
- Attribution tells you which touchpoints a platform claims led to a conversion.
- Incrementality tells you which conversions would not have happened without the ad.
These are fundamentally different questions. Attribution is a reporting convention. Incrementality is a causal claim.
To answer the causal question, we need experimentation.
Our Analytical Approach
We will use an Interrupted Time Series (ITS) design, a quasi-experimental method that tests whether a real change occurred at a known intervention point.
The logic is straightforward:
- Model the pre-intervention trend in the outcome variable
- Project what would have happened if the intervention never occurred (the counterfactual)
- Compare the actual post-intervention data to that counterfactual
- Quantify the difference and its uncertainty
If there is no meaningful difference, the intervention had no causal effect on the outcome.
We will use CausalPy, an open-source Python library for causal inference in quasi-experimental settings. It makes Bayesian causal analysis accessible without requiring heavy infrastructure, making it a good entry point for teams looking to move beyond attribution.
CausalPy version: 0.8.0Simulating the Scenario
We simulate 395 days of daily data: a full year of pre-intervention history (365 days) followed by 30 days after the attribution change. The start date is March 3, 2025, placing the intervention exactly on March 3, 2026, the date of Meta’s announcement.
Actual sign-ups (ground truth): a slight upward trend, weekly seasonality (lower on weekends), yearly seasonality (summer peaks, winter dips), and noise. Crucially, there is no change after the intervention. The business is performing the same as before.
Meta-reported conversions: a fraction of actual sign-ups that Meta’s attribution claims credit for, plus its own reporting noise. Pre-intervention, Meta attributes roughly 75% of real sign-ups (counting all click types). After the intervention, the narrower link-click-only definition drops this to roughly 55%.
We also pre-compute Fourier features for both yearly and weekly cycles. These give the ITS model smooth, flexible basis functions to capture seasonality. They tend to be more robust than monthly dummies when daily data does not break cleanly at calendar boundaries.
Show data simulation code
np.random.seed(46)
n_days = 395
intervention_day = 365
t = np.arange(n_days)
dates = pd.date_range("2025-03-03", periods=n_days, freq="D")
month = dates.month
dow = dates.dayofweek
month_effect = np.array([-5, -3, 0, 3, 5, 8, 6, 4, 2, 0, -2, -4])
monthly_seasonality = np.array([month_effect[m - 1] for m in month])
weekend_dip = np.where(dow >= 5, -6, 0).astype(float)
trend = 0.03 * t
noise_signups = np.random.normal(0, 2, n_days)
base = 100
true_signups = base + trend + monthly_seasonality + weekend_dip + noise_signups
attribution_rate_pre = 0.75
attribution_rate_post = 0.55
noise_platform = np.random.normal(0, 2, n_days)
reported = true_signups * attribution_rate_pre + noise_platform
reported[intervention_day:] = (
true_signups[intervention_day:] * attribution_rate_post
+ noise_platform[intervention_day:]
)
df = pd.DataFrame({
"date": dates,
"signups": true_signups,
"meta_reported_conversions": reported,
"t": t,
})
for k in range(1, 4):
df[f"sin_yearly_{k}"] = np.sin(2 * np.pi * k * t / 365.25)
df[f"cos_yearly_{k}"] = np.cos(2 * np.pi * k * t / 365.25)
for k in range(1, 4):
df[f"sin_weekly_{k}"] = np.sin(2 * np.pi * k * t / 7)
df[f"cos_weekly_{k}"] = np.cos(2 * np.pi * k * t / 7)
print(f"Total days: {n_days}, Intervention at day: {intervention_day}")
print(f"Pre-intervention: {intervention_day} days, Post-intervention: {n_days - intervention_day} days")
print(f"Date range: {dates[0].date()} to {dates[-1].date()}")
print(f"Intervention date: {dates[intervention_day].date()}")
df.head()Total days: 395, Intervention at day: 365
Pre-intervention: 365 days, Post-intervention: 30 days
Date range: 2025-03-03 to 2026-04-01
Intervention date: 2026-03-03The Platform View
Show plotting code
fig, ax = plt.subplots(figsize=(12, 5))
ax.plot(df["date"], df["meta_reported_conversions"], linewidth=1)
ax.axvline(x=dates[intervention_day], linestyle="--", linewidth=1, label="Attribution Change")
ax.set_title("Platform-Reported Conversions (What Marketers See)", fontsize=14, fontweight="bold")
ax.set_xlabel("Date")
ax.set_ylabel("Reported Conversions")
ax.legend()
plt.tight_layout()
plt.show()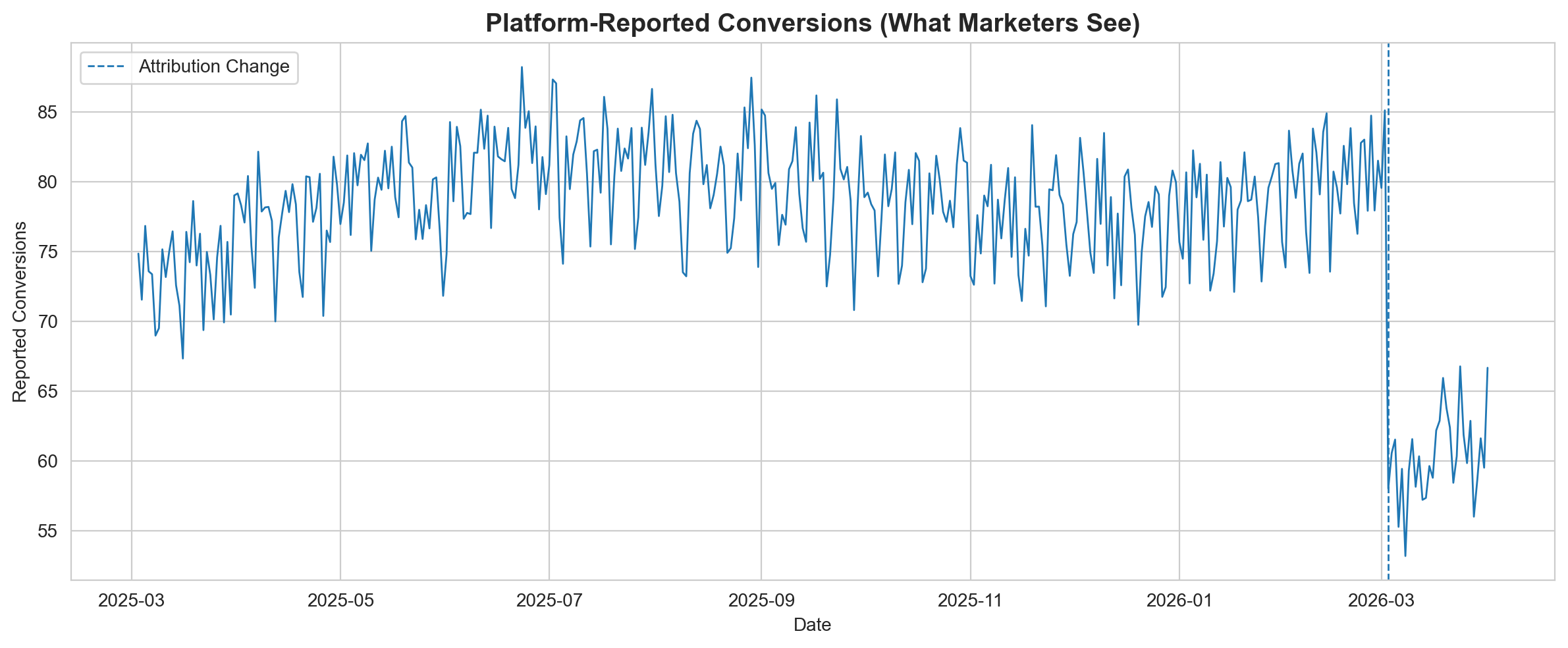
This is what shows up in Ads Manager. A clear, visible drop.
If you are a marketer staring at this chart, the instinct is immediate:
- Cut the budget because something is clearly broken
- Pause campaigns to stop the bleeding
- Swap creatives because the current ones must have stopped working
All of these reactions are rational given the data you are looking at. But what if the data is wrong?
The Ground Truth
Show plotting code
fig, ax = plt.subplots(figsize=(12, 5))
ax.plot(df["date"], df["signups"], linewidth=1)
ax.axvline(x=dates[intervention_day], linestyle="--", linewidth=1, label="Attribution Change")
ax.set_title("Actual Sign-ups (Ground Truth)", fontsize=14, fontweight="bold")
ax.set_xlabel("Date")
ax.set_ylabel("Sign-ups")
ax.legend()
plt.tight_layout()
plt.show()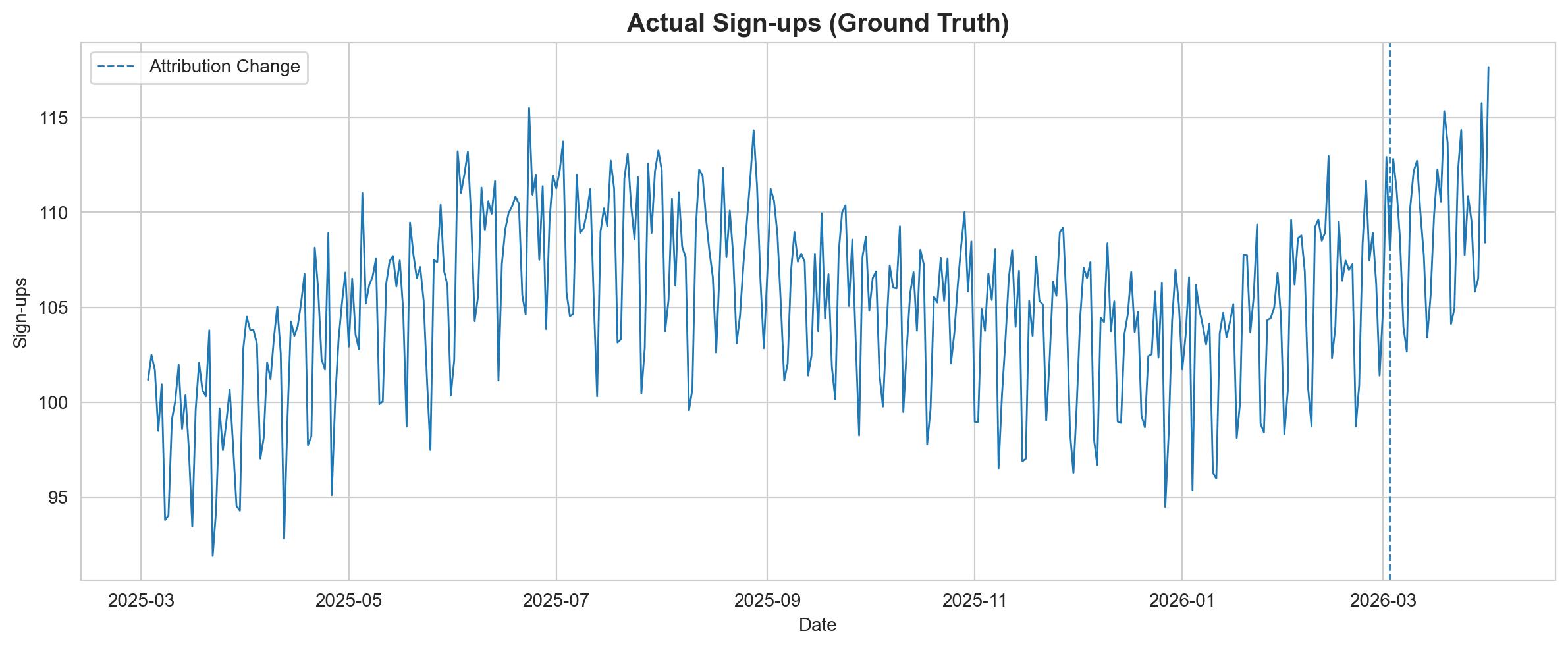
No drop. The business is performing exactly as it was before.
The trend continues upward. The seasonality pattern is unchanged. The attribution change affected what was reported, not what actually happened.
But visual inspection alone is not enough. We need to test this formally.
Interrupted Time Series Analysis
We run an ITS model on actual sign-ups (the ground truth) to test whether there was a statistically meaningful change at the intervention point.
The model learns the pre-intervention trend and projects a counterfactual into the post-intervention period. If the observed data falls within the counterfactual’s uncertainty bands, we have no evidence of a real change.
yearly_terms = " + ".join(
f"sin_yearly_{k} + cos_yearly_{k}" for k in range(1, 4)
)
weekly_terms = " + ".join(
f"sin_weekly_{k} + cos_weekly_{k}" for k in range(1, 4)
)
formula = f"signups ~ 1 + t + {yearly_terms} + {weekly_terms}"
print(f"Formula: {formula}")
result = cp.InterruptedTimeSeries(
df,
treatment_time=intervention_day,
formula=formula,
model=cp.pymc_models.LinearRegression(
sample_kwargs={"random_seed": 46, "progressbar": False}
),
)Formula: signups ~ 1 + t + sin_yearly_1 + cos_yearly_1 + sin_yearly_2 + cos_yearly_2 + sin_yearly_3 + cos_yearly_3 + sin_weekly_1 + cos_weekly_1 + sin_weekly_2 + cos_weekly_2 + sin_weekly_3 + cos_weekly_3Show plotting code
fig, ax = result.plot()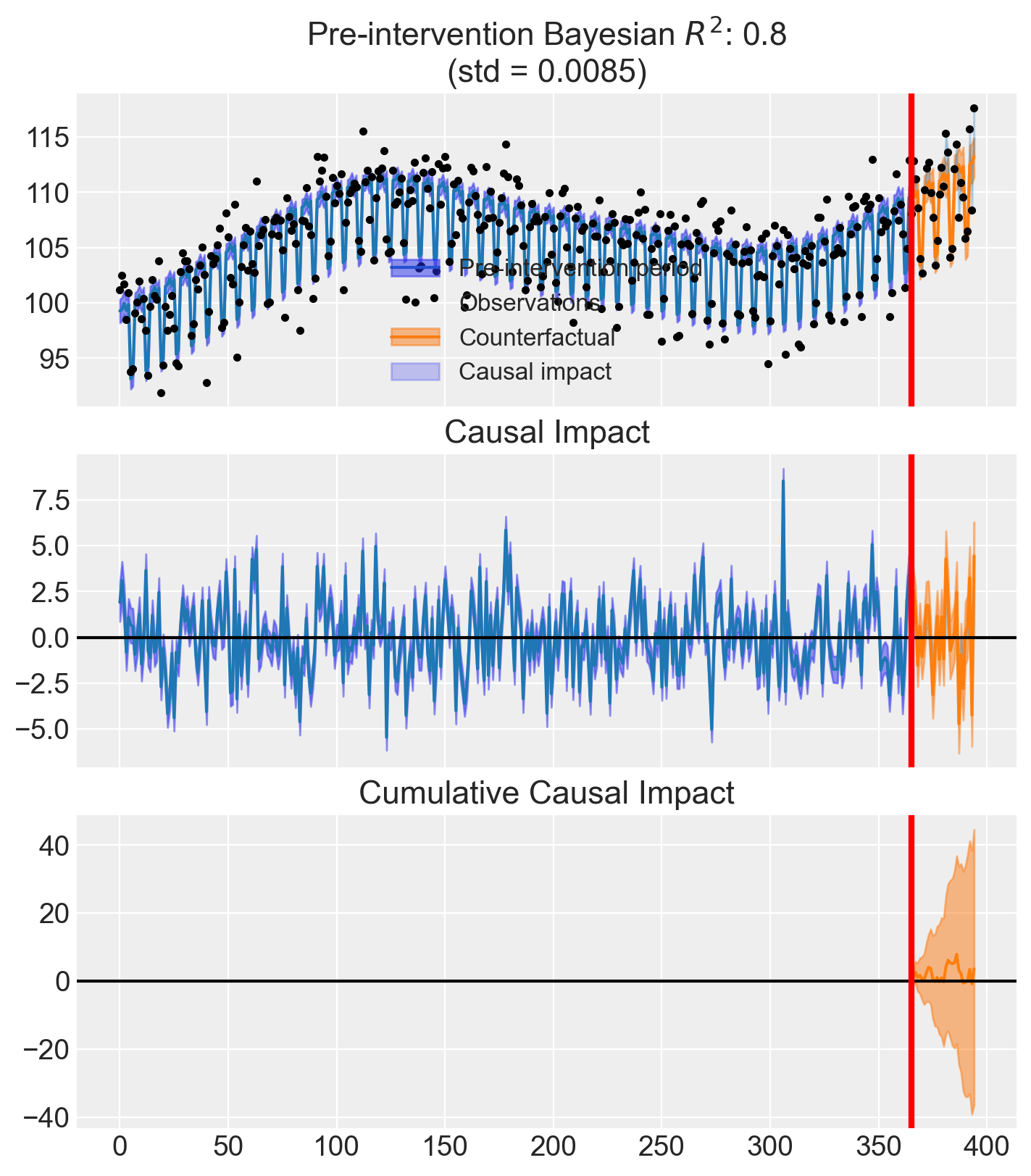
result.summary()==================================Pre-Post Fit==================================
Formula: signups ~ 1 + t + sin_yearly_1 + cos_yearly_1 + sin_yearly_2 + cos_yearly_2 + sin_yearly_3 + cos_yearly_3 + sin_weekly_1 + cos_weekly_1 + sin_weekly_2 + cos_weekly_2 + sin_weekly_3 + cos_weekly_3
Model coefficients:
Intercept 1e+02, 94% HDI [99, 101]
t 0.028, 94% HDI [0.024, 0.033]
sin_yearly_1 4.8, 94% HDI [4.2, 5.4]
cos_yearly_1 -2.4, 94% HDI [-2.7, -2.2]
sin_yearly_2 -0.031, 94% HDI [-0.41, 0.37]
cos_yearly_2 -0.33, 94% HDI [-0.61, -0.054]
sin_yearly_3 -0.052, 94% HDI [-0.39, 0.29]
cos_yearly_3 0.42, 94% HDI [0.14, 0.71]
sin_weekly_1 3.4, 94% HDI [3.1, 3.7]
cos_weekly_1 -0.72, 94% HDI [-0.99, -0.43]
sin_weekly_2 1, 94% HDI [0.74, 1.3]
cos_weekly_2 2, 94% HDI [1.7, 2.3]
sin_weekly_3 -0.92, 94% HDI [-1.2, -0.64]
cos_weekly_3 0.56, 94% HDI [0.28, 0.83]
y_hat_sigma 2, 94% HDI [1.9, 2.2]stats = result.effect_summary()
print(stats.text)During the Post-period (365 to 394), the response variable had an average value of approx. 109.62. By contrast, in the absence of an intervention, we would have expected an average response of 109.50. The 95% interval of this counterfactual prediction is [108.05, 110.87]. Subtracting this prediction from the observed response yields an estimate of the causal effect the intervention had on the response variable. This effect is 0.12 with a 95% interval of [-1.25, 1.57].
Summing up the individual data points during the Post-period, the response variable had an overall value of 3288.64. By contrast, had the intervention not taken place, we would have expected a sum of 3285.02. The 95% interval of this prediction is [3241.53, 3326.12].
The 95% HDI of the effect [-1.25, 1.57] includes zero. The posterior probability of an increase is 0.560. Relative to the counterfactual, the effect represents a 0.11% change (95% HDI [-1.13%, 1.45%]).
This analysis assumes that the relationship between the time-based predictors and the response observed during the pre-intervention period remains stable throughout the post-intervention period. If the formula includes external covariates, it further assumes they were not themselves affected by the intervention. We recommend inspecting model fit, examining pre-intervention trends, and conducting sensitivity analyses (e.g., placebo tests) to support any causal conclusions drawn from this analysis.Interpreting the Results
The CausalPy effect summary above gives us a direct, quantitative answer.
The model compares observed sign-ups after the attribution change to what it would have expected based on the pre-intervention trend. The credible interval for the causal effect includes zero, meaning there is no statistically meaningful evidence that sign-ups changed.
To put it plainly:
| Source | Says | Reality |
|---|---|---|
| Meta Ads Manager | Performance dropped ~20% | Measurement changed |
| Actual sign-ups + ITS | No significant change | Business unaffected |
The platform said one thing. The experiment said another. They cannot both be right, and only one of them is measuring what actually matters.
Business Implications
If a team relied solely on platform metrics to make decisions after this attribution change, they might:
- Cut budget on campaigns that are actually performing well
- Pause strong campaigns because reported conversions look low
- Change creatives that were working, introducing unnecessary risk
- Reallocate spend to other channels based on a false comparison
Every one of these decisions would be ill-informed. Not because the team is incompetent, but because the data they relied on was never designed to answer the question they were asking.
Platform attribution answers: “What did the platform observe?”
Business decisions require: “What actually caused this outcome?”
Key Takeaway
Attribution tells you what a platform sees. Experimentation tells you what actually caused outcomes.
These are not interchangeable.
- Attribution is unstable, platform-controlled, cookie-dependent, and subject to redefinition at any time. It is a reporting convention, not a measurement of truth.
- Experimentation is causal, decision-ready, and grounded in statistical evidence. It answers the question that actually matters: did this action cause a change in outcomes?
The Meta attribution update is not the problem. The change is defensible. Aligning click-through attribution with what third-party tools report reduces confusion. The issue is relying too heavily on the wrong metrics to make decisions that directly affect your business.
Attribution definitions will change again. They always do. The question is whether your measurement approach is resilient enough to tell the difference between a real performance shift and a reporting artifact.
Experimentation is not optional. It is the only way to know what is actually working.
Getting Started with Experimentation
CausalPy makes causal inference accessible without requiring heavy infrastructure. It supports a range of quasi-experimental designs (interrupted time series, difference-in-differences, synthetic control, regression discontinuity, and more), all with Bayesian uncertainty quantification built in.
For teams that have not yet invested in experimentation, it is a practical entry point. You do not need a full experimentation platform to start answering causal questions. You need data, a plausible design, and the right tools.
For a deeper dive into the Bayesian ITS methodology used in this analysis, see the full Bayesian Interrupted Time Series tutorial in the CausalPy documentation.
If you’re thinking about how to bring experimentation in-house and would like support doing so, reach out at jakepiekarski@jtp-analytics.com or fire me a message on LinkedIn.